Noise Reduction Demo
The clean speech signal is taken from the TIMIT corpus [1] while the noise signals are taken from Noisex [2] and Sound Effects Library [3]. In the examples, anechoic speech signals are corrupted by noise at the required SNR at each microphone.
The algorithms used in the comparison include
- Log-MMSE [4],
- Single-channel subspace for coloured noise (COLSUB) [5]
- Multi-channel subspace method (MCSUB) [6]
- Multi-channel Wiener filter (MWF) [7] in [8] which uses the Relative Transfer Function (RTF) estimator in [9] and the noise estimator in [10]
- Oracle-MWF (OMWF) that uses the clean speech signal (ground truth) [7]
- PEVD which uses the Sequential Matrix Diagonalisation algorithm [11]
- Generalized Weighted Prediction Error (GWPE) [12].
- Weighted Power minimisation Distortionless beamformer (WPD) [13] which uses the ground-truth direction-of-arrivals (DoAs) to compute the steering vector
- Integrated Sidelobe Canceller and Linear Prediction Kalman filter (ISCLP) [14].
Audio Examples
The audio player is built using the trackswitch.js tool in [15].
Noise reduction for speech in -5 dB babble noise from Noisex.
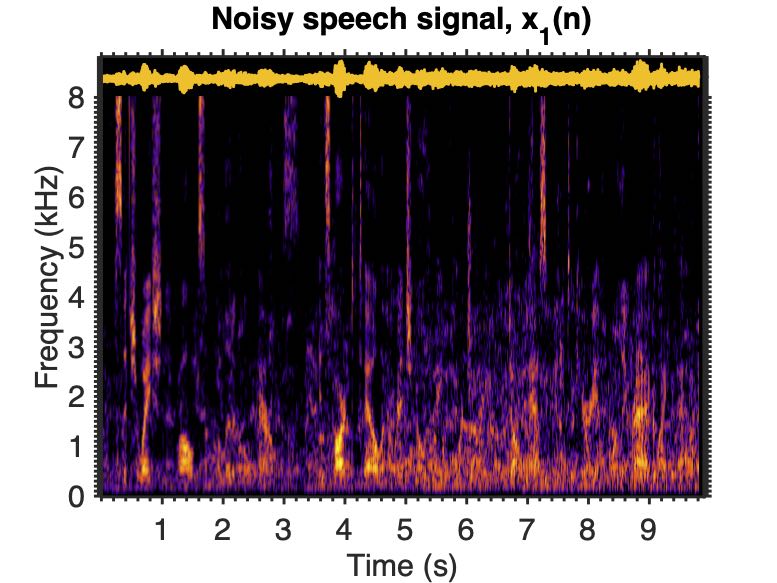
Noise reduction for speech in 0 dB babble noise from Noisex.
Noise reduction for speech in 5 dB babble noise from Noisex.
Noise reduction for speech in 20 dB babble diffuse noise from Noisex.
Noise reduction for speech in -5 dB factory noise from Noisex.
Noise reduction for speech in 5 dB factory noise from Noisex.
Noise reduction for speech in 20 dB factory noise from Noisex.
Noise reduction for speech in -5 dB car noise from Noisex.
Noise reduction for speech in 5 dB car noise from Noisex.
Noise reduction for speech in 20 dB car noise from Noisex.
Noise reduction for speech in -5 dB white noise.
Noise reduction for speech in 5 dB white noise.
Noise reduction for speech in 20 dB white noise.
Noise reduction for speech in -5 dB residential traffic noise from SoundFx.
Noise reduction for speech in 5 dB residential traffic noise from SoundFx.
Noise reduction for speech in 20 dB residential traffic noise from SoundFx.
Noise reduction for speech in -5 dB city traffic noise from SoundFx.
Noise reduction for speech in 5 dB city traffic noise from SoundFx.
Noise reduction for speech in 20 dB city traffic noise from SoundFx.
Noise reduction for speech in -5 dB city street noise from SoundFx.
Noise reduction for speech in 5 dB city street noise from SoundFx.
Noise reduction for speech in 20 dB city street noise from SoundFx.
Noise reduction for speech in -5 dB restaurant noise from SoundFx.
Noise reduction for speech in 5 dB restaurant noise from SoundFx.
Noise reduction for speech in 20 dB restaurant noise from SoundFx.
References
[1] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallet, N. L. Dahlgren, and V. Zue, "TIMIT acoustic-phonetic continuous speech corpus," Linguistic Data Consortium (LDC), Philadelphia, Corpus, 1993.
[2] A. Varga and H. J. M. Steeneken, “Assessment for automatic speech recognition II: NOISEX-92: A database and experiment to study the effect of additive noise on speech recognition systems,” Apeech Commun., vol. 3, no. 3, pp. 247-251, Jul. 1993.
[3] S. Ideas, “International Sound Effects Library,” Richmond Hill, Ont, 1999.
[4] Y. Ephraim and D. Malah, “Speech enhancement using a minimum mean-square error log-spectral amplitude estimator,” IEEE Trans. Acoust., Speech, Signal Process., vol. 33, no. 2, pp. 443–445, 1985.
[5] Y. Hu, and P. C. Louizou, “A subspace approach for enhancing speech corrupted by colored noise”, IEEE Signal Process. Lett., vol. 9, no. 7, pp. 204-206, Jul. 2002.
[6] Y. Huang, J. Chen, and J. Benesty, “Analysis and comparison of multichannel noise reduction methods in a common framework”, IEEE Trans. Audio, Speech, Lang. Process., vol. 16, no. 5, pp. 957-968, Jul. 2008.
[7] S. Doclo and M. Moonen, “GSVD-based optimal filtering for single and multimicrophone speech enhancement,” IEEE Trans. Signal Process., vol. 50, no. 9, pp. 2230–2244, Sept. 2002.
[8] A. Kuklasiriski, S. Doclo, S. H. Jensen, and J. Jensen, “Maximum likelihood PSD estimation for speech enhancement in reverberation and noise,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 9, pp. 1599-1612, Sept. 2016.
[9] V., Reza, M. Taseska, and E. Habets, "An iterative multichannel subspace-based covariance subtraction method for relative transfer function estimation." Hands-free Speech Communications and Microphone Arrays (HSCMA), 2017.
[10] Souden, M., Jingdong Chen, J. Benesty, and S. Affes," An integrated solution for online multichannel noise tracking and reduction," IEEE Trans. Audio, Speech, and Lang. Process., vol. 19, no. 7, Sept. 2011.
[11] S. Redif, S. Weiss, and J. G. McWhirter, “Sequential matrix diagonalisation algorithms for polynomial EVD of para-Hermitian matrices,” IEEE Trans. Signal Process., vol. 63, no. 1, pp. 81–89, Jan. 2015.
[12] T. Yoshioka, and T. Nakatani, “Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening,” IEEE Trans. Audio, Speech, and Lang. Process., vol. 20, no. 10, pp. 2707-2720, Dec. 2012.
[13] T. Nakatani, and K. Kinoshita “A unified convolutional beamformer for simultaneous denoising and dereverberation,” IEEE Signal Process. Lett., vol. 26, no. 6, pp. 903-907, Jun. 2019.
[14] T. Dietzen, S. Doclo, M. Moonen, and T. van Waterschoot, “Integrated sidelobe cancellation and linear prediction Kalman filter for joint multi-microphone speech dereverberation, interfering speech cancellation, and noise reduction,” IEEE Trans. Audio, Speech, and Lang. Process., vol. 28, pp. 740-754, Jan. 2020. [Online]. Available: https://github.com/tdietzen/ISCLP-KF
Related Works on PEVD Algorithms
[15] J. G. McWhirter, P. D. Baxter, T. Cooper, S. Redif, and J. Foster, “An EVD algorithm for para-Hermitian polynomial matrices,” IEEE Trans. Signal Process., vol. 55, no. 5, pp. 2158–2169, May 2007.
[16] V. W. Neo and P. A. Naylor, “Second order sequential best rotation algorithm with Householder transformation for polynomial matrix eigenvalue decomposition,” in Proc. IEEE Int. Conf. on Acoust., Speech and Signal Process. (ICASSP), 2019.
[17] S. Redif, S. Weiss, and J. G. McWhirter, “An approximate polynomial matrix eigenvalue decomposition algorithm for para-Hermitian matrices,” in Proc. Intl. Symp. on Signal Process. and Inform. Technology (ISSPIT), 2011, pp. 421–425.
Listening examples audio tool
[18] N. Werner, S. Balke, F.-R. Stöter, M. Müller, B. Edler, "trackswitch.js: A Versatile Web-Based Audio Player for Presenting Scientific Results." 3rd web audio conference, London, UK. 2017. [Online]. Available: https://github.com/audiolabs/trackswitch.js